Компания StarWind, выпускающая продукт номер 1 для создания отказоустойчивых iSCSI-хранилищ для виртуализации StarWind Enterprise HA, на прошлой неделе выпустила новый продукт для создания кластера хранилищ виртуальных машин StarWind Native SAN for Microsoft Hyper-V (подробнее тут и тут). Отличительной особенностью продукта является то, что он позволяет орагнизовать отказоустойчивую конфигурацию серверов и хранилищ на базе всего лишь 2-х серверов Hyper-V, что в 2 раза сокращает затраты на оборудование (серверы, коммутаторы) и обслуживание решения.
Таги: StarWind, SAN, Hyper-V, iSCSI, Storage, HA, TCO, VMachines
Скоро нам придется участвовать в интереснейшем проекте - построение "растянутого" кластера VMware vSphere 5 на базе технологии и оборудования EMC VPLEX Metro с поддержкой возможностей VMware HA и vMotion для отказоустойчивости и распределения нагрузки между географически распределенными ЦОД.
Вообще говоря, решение EMC VPLEX весьма новое и анонсировано было только в прошлом году, но сейчас для нашего заказчика уже едут модули VPLEX Metro и мы будем строить active-active конфигурацию ЦОД (расстояние небольшое - где-то 3-5 км) для виртуальных машин.
Для начала EMC VPLEX - это решение для виртуализации сети хранения данных SAN, которое позволяет объединить ресурсы различных дисковых массивов различных производителей в единый логический пул на уровне датацентра. Это позволяет гибко подходить к распределению дискового пространства и осуществлять централизованный мониторинг и контроль дисковых ресурсов. Эта технология называется EMC VPLEX Local:
С физической точки зрения EMC VPLEX Local представляет собой набор VPLEX-директоров (кластер), работающих в режиме отказоустойчивости и балансировки нагрузки, которые представляют собой промежуточный слой между SAN предприятия и дисковыми массивами в рамках одного ЦОД:
В этом подходе есть очень много преимуществ (например, mirroring томов двух массивов на случай отказа одного из них), но мы на них останавливаться не будем, поскольку нам гораздо более интересна технология EMC VPLEX Metro, которая позволяет объединить дисковые ресурсы двух географически разделенных площадок в единый пул хранения (обоим площадкам виден один логический том), который обладает свойством катастрофоустойчивости (и внутри него на уровне HA - отказоустойчивости), поскольку данные физически хранятся и синхронизируются на обоих площадках. В плане VMware vSphere это выглядит так:
То есть для хост-серверов VMware ESXi, расположенных на двух площадках есть одно виртуальное хранилище (Datastore), т.е. тот самый Virtualized LUN, на котором они видят виртуальные машины, исполняющиеся на разных площадках (т.е. режим active-active - разные сервисы на разных площадках но на одном хранилище). Хосты ESXi видят VPLEX-директоры как таргеты, а сами VPLEX-директоры являются инициаторами по отношению к дисковым массивам.
Все это обеспечивается технологией EMC AccessAnywhere, которая позволяет работать хостам в режиме read/write на массивы обоих узлов, тома которых входят в общий пул виртуальных LUN.
Надо сказать, что технология EMC VPLEX Metro поддерживается на расстояниях между ЦОД в диапазоне до 100-150 км (и несколько более), где возникают задержки (latency) до 5 мс (это связано с тем, что RTT-время пакета в канале нужно умножить на два для FC-кадра, именно два пакета необходимо, чтобы донести операцию записи). Но и 150 км - это вовсе немало.
До появления VMware vSphere 5 существовали некоторые варианты конфигураций для инфраструктуры виртуализации с использованием общих томов обоих площадок (с поддержкой vMotion), но растянутые HA-кластеры не поддерживались.
С выходом vSphere 5 появилась технология vSphere Metro Storage Cluster (vMSC), поддерживаемая на сегодняшний день только для решения EMC VPLEX, но поддерживаемая полностью согласно HCL в плане технологий HA и vMotion:
Обратите внимание на компонент посередине - это виртуальная машина VPLEX Witness, которая представляет собой "свидетеля", наблюдающего за обоими площадками (сам он расположен на третьей площадке - то есть ни на одном из двух ЦОД, чтобы его не затронула авария ни на одном из ЦОД), который может отличить падения линка по сети SAN и LAN между ЦОД (экскаватор разрезал провода) от падения одного из ЦОД (например, попадание ракеты) за счет мониторинга площадок по IP-соединению. В зависимости от этих обстоятельств персонал организации может предпринять те или иные действия, либо они могут быть выполнены автоматически по определенным правилам.
Теперь если у нас выходит из строя основной сайт A, то механизм VMware HA перезагружает его ВМ на сайте B, обслуживая их ввод-вывод уже с этой площадки, где находится выжившая копия виртуального хранилища. То же самое у нас происходит и при массовом отказе хост-серверов ESXi на основной площадке (например, дематериализация блейд-корзины) - виртуальные машины перезапускаются на хостах растянутого кластера сайта B.
Абсолютно аналогична и ситуация с отказами на стороне сайта B, где тоже есть активные нагрузки - его машины передут на сайт A. Когда сайт восстановится (в обоих случаях с отказом и для A, и для B) - виртуальный том будет синхронизирован на обоих площадках (т.е. Failback полностью поддерживается). Все остальные возможные ситуации отказов рассмотрены тут.
Если откажет только сеть управления для хостов ESXi на одной площадке - то умный VMware HA оставит её виртуальные машины запущенными, поскольку есть механизм для обмена хартбитами через Datastore (см. тут).
Что касается VMware vMotion, DRS и Storage vMotion - они также поддерживаются при использовании решения EMC VPLEX Metro. Это позволяет переносить нагрузки виртуальных машин (как вычислительную, так и хранилище - vmdk-диски) между ЦОД без простоя сервисов. Это открывает возможности не только для катастрофоустойчивости, но и для таких стратегий, как follow the sun и follow the moon (но 100 км для них мало, специально для них сделана технология EMC VPLEX Geo - там уже 2000 км и 50 мс latency).
Самое интересное, что скоро приедет этот самый VPLEX на обе площадки (где уже есть DWDM-канал и единый SAN) - поэтому мы все будем реально настраивать, что, безусловно, круто. Так что ждите чего-нибудь про это дело интересного.
Таги: VMware, HA, Metro, EMC, Storage, vMotion, DRS, VPLEX
Мы уже много писали о новом продукте StarWind Native SAN for Hyper-V, который позволит создать кластер отказоустойчивости серверов и хранилищ для виртуальных машин Hyper-V, используя всего 2 хост-сервера (это намного дешевле традиционных решений).
Напоминаем, что продукт выходит завтра, 18 октября.
Вебинар: "StarWind Native SAN for Hyper-V: конвергенция гипервизора и СХД"
18 октября, вторник
StarWind Native SAN for Hyper-V работает на локальном Hyper-V сервере и обеспечивает высокую доступность СХД при минимальных затратах и простоте развёртывания. Продукт идеально подходит для представителей малого и среднего бизнеса, которые не могут позволить себе аппаратные СХД, но хотят использовать следующие преимущества Hyper-V кластера:
Высокая доступность
Защита от сбоя жесткого диска
Защита от единой точки отказа. Безшовная интеграция с Hyper-V
Одно из существенных изменений, Datastore Heartbeating - механизм, позволяющий мастер-серверу определять состояния хост-серверов VMware ESXi, изолированных от сети, но продолжающих работу с хранилищами. Напомним, что в качестве heartbeat-хранилищ выбираются два, и они могут быть определены пользователем. Выбираются они так: во-первых, они должны быть на разных массивах, а, во-вторых, они должны быть подключены ко всем хостам.
Если у вас доступно общее хранилище только одно, вы получите такое предупреждение в vSphere Client:
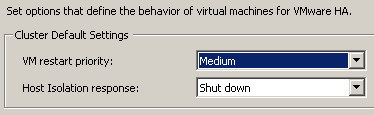
Теперь еще один момент, на который хочется обратить внимание. Помните, что в настройках VMware HA есть варианты выбора действия для хост-сервера по отношении к своим виртуальным машинам в том случае, когда он обнаруживает, что изолирован от сети (параметр Isolation Responce):
Напомним, что Isolation Responce может принимать следующие значения:
Leave powered on (по умолчанию в vSphere 5 - оптимально для большинства сценариев)
Power off
Shutdown
Выбирать правильную настройку нужно следующим образом:
Если наиболее вероятно что хост ESXi отвалится от общей сети, но сохранит коммуникацию с системой хранения, то лучше выставить Power off или Shutdown, чтобы он мог погасить виртуальную машину, а остальные хосты перезапустили бы его машину с общего хранилища после очистки локов на томе VMFS или NFS (вот кстати, что происходит при отваливании хранища).
Если вы думаете, что наиболее вероятно, что выйдет из строя сеть сигналов доступности (например, в ней нет избыточности), а сеть виртуальных машин будет функционировать правильно (там несколько адаптеров) - ставьте Leave powered on.
Разницу между Power off и Shutdown многие из вас знают - во втором случае машина выключается средствами гостевой системы, а в первом случае - это жесткое выключение средствами хост-сервера. Казалось бы, лучше всего ставить второй вариант (Shutdown). Но это не всегда так. Дело в том, что при действии shutdown у гостевой ОС может не получиться погасить систему (например, вылетит exception или еще что). В этом случае хост ESXi будет пытаться сделать shutdown в течение 5 минут до того, как он уже сделает действие power off.
Это приведет к тому, что время восстановления работоспособности сервиса вполне может увеличиться на 5 минут, что может быть критично для некоторых задач (с высокими требованиями к RTO). Зато в случае shutdown у вас произойдет корректное завершение работы сервера, а при power off могут не сохраниться данные, нарушиться консистентность и т.п. Выбирайте.
В первой части статьи мы уже рассматривали наиболее оптимальную конфигурацию средства VMware vSphere Storage Appliance для создания отказоустойчивого кластера хранилищ из трех хостов и описали, что происходит с хранилищами при отказе сети синхронизации (Back-End Network). Во второй части статьи мы расскажем о том, как конфигурация VSA отрабатывает отказ сети управления и экспорта NFS-хранилищ (Front-End).
Мы уже писали о том, что такое виртуальный модуль VMware VSA, и как он работает в случае отключения сети синхронизации между хост-серверами VMware ESXi. Сегодня приведем несколько полезных материалов.
Во-первых, это документ "Performance of VSA in VMware Sphere 5", рассказывающий об основных аспектах производительности продукта. В нем приведен пример тестирования VSA на стенде с помощью различных инструментов.
Всем интересующимся производительностью VSA для различных типов локальных хранилищ и рабочих нагрузок в виртуальных машинах документ рекомендуется к прочтению.
Во-вторых, появилось интересное видео о том, как VMware VSA реагирует на отключение сети синхронизации хранилищ и сети управления VSA.
Отключение Front-end сети (управление виртуальным модулем и NFS-сервер):
Отключение Back-end сети (зеркалирование хранилищ, коммуникация в кластере):
Ну и, в-третьих, хочу напомнить, что до 15 декабря при покупке VMware vSphere 5 Essentials Plus + VSA вместе действует скидка 40% на модуль VSA.
Таги: VMware, VSA, Performance, Storage, vSphere, HA, SMB, Video
Как мы уже писали тут, тут и тут, компания StarWind, выпускающая продукт номер 1 для создания отказоустойчивых хранилищ iSCSI для виртуальной инфраструктуры, выходит на рынок с новым решением - StarWind Native SAN for Hyper-V.
Основная идея продукта - дать пользователям возможность строить кластер отказоустойчивости серверов и хранилищ на базе двух серверов Hyper-V вместо четырех. Это сократит издержки на покупку оборудования и обслуживание решения при увеличении производительности (рекомендуется использовать адаптеры 10G).
Интересно посмотреть на расчеты по экономической составляющей решения - затраты уменьшаются почти в два раза (не нужно покупать еще 2 сервера, использовать порты коммутаторов, меньше тратится электричества и проще обслуживание). У компании StarWind есть подробное описание статей затрат:
Расчеты выглядят вполне правдоподобно. Все это приводит к тому, что стоимость капитальных и эксплуатационных затрат на содержание одного приложения снижается на 20-30%.
Немного скорректировалась дата выхода продукта StarWind Native SAN for Hyper-V - он появится 18 октября (записаться на получение можно тут).
Таги: StarWind, iSCSI, Hyper-V, SAN, Storage, HA, Update, TCO
Мы уже писали о новом продукте VMware vSphere Storage Appliance (VSA), который позволяет создать кластер хранилищ на базе трех серверов (3 хоста ESXi 5 или 2 хоста ESXi 5 + физ. хост vCenter), а также о его некоторых особенностях. Сегодня мы рассмотрим, как работает кластер VMware VSA, и как он реагирует на пропадание сети на хосте (например, поломка адаптеров) для сети синхронизации VSA (то есть та, где идет зеркалирование виртуальных хранилищ).
Таги: VMware, VSA, vSphere, Обучение, ESXi, Storage, HA, Network
Продолжаем рассказывать о решении номер 1 для создания отказоустойчивых кластеров серверов и хранилищ - StarWind Native SAN for Hyper-V. Напомню, что это решение позволит вам, используя всего 2 сервера и несколько сетевых адаптеров, создать надежное общее iSCSI-хранилище для виртуальных машин Hyper-V с поддержкой Live Migration и другой функциональности платформы виртуализации:
То есть и машины исполняются на этих серверах, и хранилища между ними синхронизированы и отказоустойчивы.
Суть такого сверхэкономного решения - это полный набор возможностей по созданию кластеров серверов и хранилищ (с полным спектром возможностей) без необходимости приобретения дополнительных коммутаторов и серверов под такую конфигурацию. По стоимости решения пока непонятно, но я думаю это будет вполне бюджетно.
В комментариях можете задавать свои вопросы - сотрудники StarWind на них обязательно ответят.
Кстати, StarWind Enterprise HA получил сертификацию "Works with Windows Server 2008 R2":
На днях компания StarWind Software, выпускающая продукт номер 1 для создания отказоустойчивых хранилищ под виртуализацию (в том числе, Hyper-V), анонсировала доступность для партнеров продукта StarWind Data Deduplication, который производители программного обеспечения могут включать как OEM в свои решения.
Это технология in-line дедупликации данных (то есть во время резервного копирования, а не после) на уровне блоков, которая уже надежно зарекомендовала себя в продукте StarWind Enterprise HA 5.7. Она позволяет добиться коэффициента дедупликации данных до 20 к 1, использует регулируемый размер блока (под разные задачи хранилищ) и позволяет использовать кэширование на SSD-накопителях и в оперативной памяти. Тот факт, что StarWind продает эту технологию как OEM, доказывает надежность этого механизма дедупликации и его производительность.
Более подробно мы писали об этой технологии здесь. Страница продукта тут.
Компания StarWind Software, выпускающая продукт StarWind Enterprise iSCSI - номер 1 на рынке для создания отказоустойчивых хранилищ для серверов VMware vSphere и Microsoft Hyper-V, продолжает развивать ветку продукта, относящуюся к платформе виртуализации Hyper-V.
Новый продукт StarWind Native SAN for Hyper-V, планируемый к выпуску 15 сентября 2011 года, представляет собой средство для создания отказоустойчивой двухузловой конфигурации хранилища iSCSI на базе двух серверов Hyper-V.
Суть нативности StarWind iSCSI SAN для Hyper-V в том, что для создания полноценного и отказоустойчивого хранилища для виртуальных машин вам не понадобится вообще больше никакого "железа", кроме этих двух серверов.
StarWind Native SAN for Hyper-V - это Windows-приложение, которое вполне может существовать на обычном Windows Server с ролью Hyper-V. Поэтому вам не нужно дополнительного бюджета, кроме денег на приобретение продукта, что весьма актуально для небольших организаций, где собственно и используется Hyper-V.
Таким образом, на базе двух серверов у вас получится кластер высокой доступности (HA) и отказоустойчивый кластер хранилищ. Это будет очень интересно.
Если вы будете на VMworld 2011, который будет на днях, вы можете подойти к стойке StarWind (под номером 661) - там будут русскоговорящие ребята, которые вам расскажут и о StarWind Native SAN for Hyper-V, и об обычном StarWind Enterprise HA для VMware vSphere (сейчас актуальна версия StarWind 5.7).
Ну а мы, в свою очередь, в скором времени поподробнее расскажем о том, как работает StarWind Native SAN for Hyper-V.
Таги: StarWind, Enterprise, SAN, Hyper-V, Storage, Hardware, HA
Как вы знаете, компания VMware в ближайшее время намерена выпустить не только VMware vSphere 5, но и новую версию продукта для создания катастрофоустойчивой инфраструктуры VMware Site Recovery Manager 5.
Помимо того, что мы уже описывали о VMware SRM 5, появился расширенный список возможностей, который приведен ниже:
Возможности Sphere Replication – техника, позволяющая делать host-based репликацию для виртуальных машин в небольших компаниях (поддерживаются не только общие тома, но и локальные хранилища серверов ESXi). Вот некоторые ограничения технологии:
Требует vSphere 5.
Управляется напрямую из vSphere client.
Смонтированные ISO-шки и Floppy-ки не реплицируются.
Машины в состоянии Powered off/Suspended не реплицируются.
Некритичные файлы тоже не реплицируются (swap files, dumps, logs и т.д.).
Виртуальная машина может иметь снапшот на защищаемом сайте, но он будет применен (смерджен) на резервном.
Физические тома RDM не поддерживаются (но виртуальные поддерживаются).
Не поддерживаются также следующие ВМ: с включенной Fault Tolerance, Linked Clones и VM Templates.
Первичная копия ВМ может быть сделана на оффлайн-носитель (например, переносной диск) - что уменьшаяет требования к каналу репликации.
Поддерживает технику создания консистентных виртуальных машин на резервном сайте (на уровне файлов, но не на уровне приложений).
Включена в обе редакции SRM: Standard и Enterprise Editions.
vSphere Replication можно использовать только в продукте SRM 5.
Улучшения масштабируемости:
До 1000 защищаемых ВМ (как и в SRM 4.1).
500 защищаемых ВМ в одной protection group (как и в SRM 4.1)
Количество Protection Groups - 250 (ранее 150 в 4.1).
30 одновременно исполняемых планов восстановления после сбоя (ранее - всего 3).
Функции Planned Migration – это выключение виртуальных машин на основном сайте, их репликация на резервный и последующее включение их там. То есть это - плановый переезд датацентра или части инфраструктуры. В этом случае сохраняется полная консистентность.
Функции Failback – теперь можно в случае аварии, восстановления на резервном сайте и последующего восстановления основного сайта, можно снова переехать на основной сайт. Делается это за счет перенаправления репликации и реверсного исполнения плана восстановления.
Улучшения интерфейса и юзабилити:
Оба датацентра теперь видятся и управляются без vCenter linked mode.
Изменения IP-адресации для ВМ во время восстановления теперь могут быть введены в GUI, без геморроя
Заглушки для резервных ВМ за резервном сайте теперь имеют уникальную иконку, чтобы идентифицировать их как заглушки, а не производственные ВМ.
Отчеты теперь включают user ID, который инициировал операции Failover или DR test.
Отчеты включают в себя больше информации о шагах по работе с дисковыми массивами (включая device friendly names)
IPv6 Support – полностью поддерживается.
IP Customization performance – заметное улучшение по скорости преобразования IP-адресов.
In guest callouts – теперь можно выполнить скрипт в ВМ, выполнить скрипт на сервере SRM или сделать брейкпоинт (точку останова) для вывода сообщения во время исполнения плана восстановления.
Новый API для обоих частей - Protected и Recovery Sides – новые команды для интеграции со сторонними приложениями и системами (на базе SOAP).
Улучшение связности – теперь есть 5 priority groups для каждого плана восстановления. Каждая группа должна полностью выполниться в рамках DR-плана, пока не будет осуществлен переход к следующей группе. В рамках каждой группы можно создавать зависимости (аналогично зависимостям в службах Windows). То есть, например, машина не начнет восстанавливаться, пока все зависимые для нее компоненты не будут восстановлены (но все это только в рамках одной группы приоритетов).
Licensing – теперь есть 2 издания SRM: Standard and Enterprise. Оба издания абсолютно идентичны. Единственная разница - это то, что в издании SRM Standard есть ограничение на 75 виртуальных машин на одной площадке. Здесь отчетливо видно, что цена в $195 за виртуальную машину для издания Standard (а значит, и для среднего и малого бизнеса) - это попытка конкурировать с продуктом Veeam Backup and Replication 5, который еще со своей первой версии умеет делать репликацию виртуальных машин между площадками.
В целом, конечно список улучшений весьма обширен. А что касается конкуренции VMware SRM 5 с Veeam Backup and Replication 5 - в плане репликации, последний пока выигрывает, так как имеет меньше функциональных ограничений (о произодительности пока сказать нельзя - SRM 5 еще не вышел). Ожидается, что VMware SRM 5 будет доступен для загрузки после 22 августа.
Таги: VMware, SRM, Update, vSphere, Replication, Veeam, Backup, HA, VMachines
Те из вас, кто следил за развитием функциональности платформы VMware vSphere, наверняка помнят, что в версии vSphere 4.1 появился такой компонент как Application Monitoring в настройках VMware High Availability (HA):
Этот компонент был реализован с помощью API, который был доступен сторонним разработчикам приложений, и позволял производить мониторинг доступности отдельных приложений в виртуальных машинах, работающих на платформе vSphere 4.1. В случае проблем с приложением (оно не обновляет Heartbeat - сигнал доступности), виртуальная машина перезагружалась.
То есть, эта технология была доступна только партнерам VMware, один из которых, компания Symantec, реализовала эту функциональность в своем продукте ApplicationHA и добавила поддержку распространенных Windows-приложений:
Теперь компания VMware в новой версии платформы VMware vSphere 5.0 решила пойти дальше и сделать механизм Application Monitoring доступным для всех.
Теперь у Application Monitoring есть свой SDK, в котором есть следующая утилита:
markActive - это функция, вызываемая со стороны приложения, которая вызывается каждые 30 секунд, что говорит о том, что приложение еще "живет". Если она прекратит вызываться, это будет означать что виртуальную машину надо перезагрузить.
isEnabled - проверить статус Application Monitoring.
getAppStatus - проверить статус защищаемого приложения.
То есть, теперь ваши разработчики, используя Java или C++, могут сами написать модуль для работы с VMware Application Monitoring в своем приложении, используя следующие функции:
VMGuestAppMonitor_Enable()
VMGuestAppMonitor_MarkActive()
VMGuestAppMonitor_Disable()
VMGuestAppMonitor_IsEnabled()
VMGuestAppMonitor_GetAppStatus()
VMGuestAppMonitor_Free()
Ну и, само собой, можно писать свои скрипты, которые могут мониторить состояние служб и других компонентов. Это отличная новость и хорошая возможность добавить еще один важный уровень высокой доступности в своей виртуальной инфраструктуре.
После создания адаптера, заходим в свойства инициатора и определяем для него байндинги:
Нажимаем Add и выбираем порты VMkernel, которые мы хотим использовать с инициатором:
Можно добавить два, если делаем отказоустойчивую конфигурацию для двух сетевых адаптеров:
Обратите внимание, что изменился интерфейс для настроек iSCSI в ESXi 5. Его мы опишем вскоре подробнее. Пока же скачивайте пробную версию StarWind Enterprise HA. Виртуальную машину VSA скачивайте здесь.
Вы уже читали, что в VMware vSphere 5 механизм отказоустойчивости виртуальных машин VMware High Availability претерпел значительные изменения. Точнее, он не просто изменился - его полностью переписали с нуля. То есть переделали совсем, изменив логику работы, принцип действия и убрав многие из существующих ограничений. Давайте взглянем поподробнее, как теперь работает новый VMware HA с агентами Fault Domain Manager...
Таги: VMware, vSphere, HA, Update, ESXi, Storage, vCenter, FDM
Вместе с релизом продуктовой линейки VMware vSphere 5, VMware SRM 5 и VMware vShield 5 компания VMware объявила о выходе еще одного продукта - VMware vSphere Storage Appliance. Основное назначение данного продукта - дать пользователям vSphere возможность создать общее хранилище для виртуальных машин, для которого будут доступны распределенные сервисы виртуализации: VMware HA, vMotion, DRS и другие.
Для некоторых малых и средних компаний виртуализация серверов подразумевает необходимость использовать общие хранилища, которые стоят дорого. VMware vSphere Storage Appliance предоставляет возможности общего хранилища, с помощью которых малые и средние компании могут воспользоваться средствами обеспечения высокой доступности и автоматизации vSphere. VSA помогает решить эти задачи без дополнительного сетевого оборудования для хранения данных.
Кстати, одна из основных идей продукта - это подвигнуть пользователей на переход с vSphere Essentials на vSphere Essentials Plus за счет создания дополнительных выгод с помощью VSA для распределенных служб HA и vMotion.
Давайте рассмотрим возможности и архитектуру VMware vSphere Storage Appliance:
Как мы видим, со стороны хостов VMware ESXi 5, VSA - это виртуальный модуль (Virtual Appliance) на базе SUSE Linux, который представляет собой служебную виртуальную машину, предоставляющую ресурсы хранения для других ВМ.
Чтобы создать кластер из этих виртуальных модулей нужно 2 или 3 хоста ESXi 5. Со стороны сервера VMware vCenter есть надстройка VSA Manager (отдельная вкладка в vSphere Client), с помощью которой и происходит управление хранилищами VSA.
Каждый виртуальный модуль VSA использует пространство на локальных дисках серверов ESXi, использует технологию репликации в целях отказоустойчивости (потому это и кластер хранилищ) и позволяет эти хранилища предоставлять виртуальным машинам в виде ресурсов NFS.
Как уже было сказано, VMware VSA можно развернуть в двух конфигурациях:
2 хоста ESXi - два виртуальных модуля на каждом хосте и служба VSA Cluster Service на сервере vCenter.
3 хоста ESXi - на каждом по виртуальному модулю (3-узловому кластеру служба на vCenter не нужна)
С точки зрения развертывания VMware VSA - очень прост, с защитой "от дурака" и не требует каких-либо специальных знаний в области SAN (но во время установки модуля на хосте ESXi не должно быть запущенных ВМ)...
Компания StarWind Software, выпускающая самый лучший продукт для создания iSCSI-хранилищ для ваших серверов VMware vSphere и Mirosoft Hyper-V (см. тут и тут), объявила о выпуске решения StarWind Enterprise 5.7, которое предоставляет еще больше возможностей по созданию отказоустойчивых хранилищ (само собой, есть бесплатная версия StarWind 5.7 Free).
Этот релиз StarWind Enterprise 5.7 представляет собой первый шаг по переводу механизма отказоустойчивости хранилищ на новую архитектуру.
Перечислим основные новые возможности StarWind 5.7:
1. Улучшения механизма синхронизации. Теперь отсылка данных между узлами отказоустойчивого кластера происходит в асинхронном режиме. Это означает, что StarWind Enterprise HA теперь работает заметно быстрее. Подробности нового механизма работы HA вы можете прочитать в блоге у Константина, а мы приведем основную суть.
Ранее все работало следующим образом:
Когда iSCSI-пакет приходит на основной узел, он отправляет его на резервный. После того, как резервный узел получает пакет, он посылает iSCSI-команду подтверждения получения блока данных (ACK), только после получения которой основной узел передает ACK инициатору и записывает пакет на диск. Когда iSCSI-команд становилось много, они ставились в очередь и происходили некоторые задержки, поскольку постоянно нужно было совершать эти итерации.
Теперь все работает так (некий гибрид синхронного и асинхронного процессов):
Когда iSCSI-пакет приходит на основной узел, он отправляет его на резервный. И, не дожидаясь ACK от партнера, сразу посылается второй пакет. Когда очередь закончится, и второй узел запишет данные на диск, он отсылает ACK основному узлу, которые его уже передает инициатору. Так все работает значительно быстрее. Ну и защита от потери данных при сбое в канале синхронизации тоже есть.
2. Улучшения High availability. Появилось управление полосой пропускания канала синхронизации (QoS) - теперь можно регулировать приоритезацию трафика при синхронизации HA-узлов, что позволяет не забивать весь доступный канал и не затормаживать доступ к общему хранилищу. Для этого нужно выбрать пункт "Sync channel priorities" из контекстного меню HA-устройства.
По умолчанию для наибольшей безопасности приоритет стоит у канала синхронизации. Выставлять QoS нужно только на основном узле, на резервном он выставится автоматически.
3. Оптимизация канала. Теперь для оптимизации канала используется несколько параллельных iSCSI-сессий. В следующей версии StarWind Enterprise 5.8 это количество можно будет регулировать, а также возможна будет настройка количества каналов для Heartbeat.
4. Performance Monitoring - возможность отслеживания производительности дисковой подсистемы из Management Console (disk transfer rate, average number of I/O operations on targets, CPU and memory load on StarWind server). Выглядит это так:
5. Новая полезная оснастка - Snapshot Manager. Теперь можно управлять снапшотами через GUI. Для этого в контекстном меню для устройства нужно выбрать пункт "Snapshot Manager".
6. Улучшенный Event log. Теперь при наступлении события происходит нотификация администратора через иконку в System Tray.
7. Улучшения GUI. Теперь Targets и серверы могут объединяться в группы для удобства управления.
8. Экспериментальный "deduplication plugin". Он позволяет установить дедупликацию с размерами блока от 512Б до 256КБ на выбор (вместо 512Б сейчас), что позволяет увеличить производительность процесса дедупликации до десяти раз, при этом экономия пространства на дедупликации уменьшается всего на 10-15% (при сравнении 512 байтовых с 4кб блоками). Кроме того, значительно понизится нагрузка на ЦПУ и 90% уменьшятся требования к объёму ОЗУ.
9. ImageFile, DiskBridge. Поддержка режима Mode Sense page 0x3 для совместимости с iSCSI-инициатором Solaris.
Компания VMware в июле 2011 года объявила о доступности новых версий целой линейки своих продуктов для облачных вычислений, среди которых находится самая технологически зрелая на сегодняшний день платформа виртуализации VMware vSphere 5.0.
Мы уже рассказывали об основном наборе новых возможностей VMware vSphere 5.0 неофициально, но сейчас ограничения на распространение информации сняты, и мы можем вполне официально рассказать о том, что нового для пользователей дает vSphere 5.
На конференции Citrix Synergy компания Citrix объявила о приобретении Kaviza (напомним, что в прошлом году Citrix сделала стратегические инвестиции в Kaviza). Это вендор, который выпускает решение VDI-in-a-box. Это такой виртуальный модуль (Virtual Appliance), который позволяет упростить процедуру внедрения VDI в небольших компаниях.
Kaviza VDI-in-a-box не требует брокеров соединений, серверов управления и балансировщиков нагрузки - все умещается в одном виртуальном модуле. Получаем вот такую картинку "до и после":
При этом решение VDI-in-a-box не требует общего хранилища для виртуальных ПК - можно использовать локальные диски серверов. Это и быстрее (локальные диски vs общее хранилище), и не требует дополнительных инвестиций в создание инфраструктуры СХД.
В продукте даже есть некий High Availability Grid Engine, который обеспечивает отказоустойчивость для виртуальных ПК на хост-серверах.
Кстати, ранее в качестве платформы поддерживались VMware vSphere, Citrix XenServer и Microsoft Hyper-V. Теперь же непонятно, оставит ли Citrix поддержку VMware, хотя логичных причин прекращать ее нет.
Также отметим, что Kaviza имеет в своем составе поддержку Linked Clones для виртуальных ПК, а в качестве протокола доступа с клиентских устройств использует RDP либо Citrix HDX.
В целом, VDI-in-a-box - штука весьма интересная и SMB-пользователи должны повнимательнее к ней присмотреться. Тем более, что под крылом Citrix продукт, будем надеяться, станет лучше.
Реселлеры смогут начать поставки VDI-in-a-box по каналам Citrix уже с 1 июля этого года. Скачать пробную версию ПО Kaviza можно по этой ссылке.
Таги: Citrix, Kaviza, VDI, SMB, VMachines, HDX, HA
Как вы уже все знаете, мы очень любим продукт StarWind Enterprise HA (о нем написано тут, тут и в разделе StarWind), который позволяет создавать отказоустойчивые хранилища для виртуальных машин на платформах VMware vSphere и Microsoft Hyper-V. Это позволяет существенно сэкономить на средствах репликации данных (например, VMware Site Recovery Manager) и не требует покупки дорогостоящих массивов Fibre Channel. То есть можно использовать существующую инфраструктуру Ethernet и дисковые массивы iSCSI, либо вообще серверы-хранилища.
Сегодня компания StarWind запустила промо-программу, в рамках которой можно купить StarWind Enterprise HA со скидкой 5% до конца июня. Продукт нужный - поэтому поторопитесь и закладывайте его в бюджет.
Механизм VMware High Availability (HA) в VMware vSphere позволяет автоматически перезапустить виртуальные машины отказавшего сервера в кластере с общего хранилища в случае сбоя. При настройке кластера VMware HA можно использовать несколько расширенных настроек (HA Advanced Settings), которые позволяют настроить его работу наиболее гибко.
Таги: VMware, HA, ESX, ESXi, Bugs, vSphere, VI, VMachines, Обучение
Как вы знаете, в механизме высокой доступности VMware High Availability (HA) есть такая настройка как Isolation Responce, которая определяет, какое событие следует выполнить хосту VMware ESX / ESXi в случае наступления события изоляции для него в кластере (когда он не получает сигналов доступности - Heartbeats - от других хост-серверов).
Leave powered on
Power off
Shutdown
Сделано это для того, чтобы вы могли выбрать наиболее вероятное событие в вашей инфраструктуре:
Если наиболее вероятно что хост ESX отвалится от общей сети, но сохранит коммуникацию с системой хранения, то лучше выставить Power off или Shutdown, чтобы он мог погасить виртуальную машину, а остальные хосты перезапустили бы его машину с общего хранилища после очистки локов на томе VMFS или NFS (вот кстати, что происходит при отваливании хранища).
Если вы думаете, что наиболее вероятно, что выйдет из строя сеть сигналов доступности (например, в ней нет избыточности), а сеть виртуальных машин будет функционировать правильно (там несколько адаптеров) - ставьте Leave powered on.
Но есть еще один момент. Как вам известно, VMware HA тесно интегрирована с технологией VMware Fault Tolerance (непрерывная доступность ВМ, даже в случае выхода физического сервера из строя). Суть интеграции такова - если хост с основной виртуальной машиной выходит из строя, то резервный хост выводит работающую резервную ВМ на себе "из тени" (она становится основной), а VMware HA презапускает копию этой машины на одном из оставшихся хостов, которая становится резервной.
Так вот настройка Isolation Responce не применяется к машинам, защищенным с помощью Fault Tolearance. То есть, если хост VMware ESX с такой машиной становится изолированным, при настройке Power off или Shutdown он такую машину не гасит, а всегда оставляет включенной.
Рекомендация - иметь network redundancy для сети heartbeats. Не должен хост себя чувствовать изолированным, если он весь не сломался.
Часто задаваемый вопрос: можно ли осуществлять резервное копирование виртуальных машин на ESX, работающих в кластере постоянной доступности VMware Fault Tolerance. Ответ прост - согласно ограничениям технологии FT, бэкап таких работающих виртуальных машин делать нельзя, поскольку для них нельзя сделать мгновенный снимок (снапшот).
А ведь, зачастую, пользователям нужна не только высокая доступность сервиса в виртуальной машине на случай аварии или других неприятностей, но и резервное копирование на случай утери критичных данных. Кстати говоря, VMware обещала сделать поддержку одного снапшота для FT-машин в целях резервного копирования, но так и не сделала этого в версии VMware vSphere 4.1. А делать бэкап надо - поэтому придется все делать самим.
Очевидных пути выхода из положения два:
1. Делать резервное копирование данных виртуальной машины средствами гостевой ОС (копирование на уровне файлов) либо средствами SAN (снапшоты).
2. На период бэкапа (например, средствами Veeam Backup) выключать защиту Fault Tolerance для виртуальной машины вручную или с помощью скрипта по расписанию. Этот способ подходит не всем, поскольку на время резервного копирования машина оказывается незащищенной.
О первом способе вы и так знаете, поэтому поговорим о втором:
Затем минут за 10-15 до запуска задачи резервного копирования отключаем Fault Tolerance для машины командой (ее можно добавить в bat-файл и запускать планировщиком):
Затем запускаем задачу резервного копирования Veeam Backup, в настройках которой есть замечательный параметр для выполнения скрипта после завершения задачи:
А вот в этом батнике мы уже снова включаем Fault Tolerance командой вроде этой:
Понятное дело, что данный способ является костылем, и скорее всего данная особенность будет исправлена в следующей версии vSphere, но пока приходится делать вот так.
Таги: VMware, FT, Backup, Fault Tolerance, vSphere, ESX, Blogs, HA
Константин Введенский, мой старый приятель и по совместительству сотрудник компании StarWind Software, опубликовал интересные заметки по оптимизации работы хранилищ виртуальных машин VMware ESX на базе продукта StarWind Enterprise. Если кто-нибудь из вас все еще не знает как StarWind может помочь вам в создании отказоустойчивых систем хранения по iSCSI для виртуальных машин серверов VMware ESX, то вам сюда, сюда, и, вообще, сюда.
О чем говорят нам эти заметки:
1. iSCSI Initiator на VMware ESX можно использовать в режиме NIC binding (то есть Teaming в настройках vSwitch), или в режиме MPIO (multipathing, в настройках политики путей к хранилищу в категории Storage), но нельзя их использовать одновременно. Еще посмотрите сюда.
2. Если вы используете и хранилища NAS/NFS, и хранилища iSCSI, то нужно использовать NIC Teaming для обоих интерфейсов, а не MPIO.
3. Для типа балансировки IP Hash вы сможете использовать только 1 iSCSI-соединение на хост VMware ESX. Как настраивается тип балансировки IP Hash изложено в KB 100737.
4. По умолчанию время выбора пути в случае отказа на VMware ESX равно 300 секунд. Это время рекомендованное VMware. Вы можете уменьшить или увеличить это время. Его уменьшение ускорит переключение на резерв, но даст нагрузку на процессор ESX (более частый опрос путей), увеличение этого времени снизит нагрузку на CPU, но и увеличит время Failover'а. Настраивается этот параметр в Advanced Settings сервера ESX - он называется Disk.PathEvalTime, и его значение может варьироваться в диапазоне от 30 до 1500. Более подробно в VMware KB 1004378 и еще вот тут посмотрите, например.
5. В виртуальных машинах Windows убедитесь, что параметр Disk\TimeOutValue в реестре равен 60 секундам. Это позволит дисковому устройству не отваливаться раньше времени. Если VMware Tools установлены, то он будет равен 60 секундам после установки, если же нет, то это будет 10 секунд (non-cluster) или 20 секунд (cluster node). Настраивается он вот в этом ключе реестра:
Для Linux все немного не так. Без VMware Tools время TimeOutValue равно 60 секундам, а с ними - 180 секундам. Настраивается TimeOutValue в Linux так:
cat /sys/block/<disk>/device/timeout
Для большинства случаев подойдет значение в 60 секунд.
6. Для достижения лучшей производительности со StarWind Enterprise лучше использовать политику балансировки нагрузки по нескольким путям Round Robin (не активирована по умолчанию, по дефолту стоит политика Fixed). Для этого нужно щелкнуть правой клавишей по устройству iSCSI и нажать "Manage Paths" в vSphere Client.
Эта политика позволяет переключаться между путями каждые 1000 IOPS'ов. Можно уменьшить это значение для оптимизации производительности. Для этого в сервисной консоли ESX / ESXi наберите:
В данном случае выставлено 3 IOPS'а. UUID девайса можно узнать в категории "Storage adapters" в vSphere Client для сервера ESX. Опросить текущие настройки устройства можно командой сервисной консоли:
esxcli nmp roundrobin getconfig --device [UUID]
Ну и, конечно, помните, что все эти настройки нужно сначала опробовать в тестовой среде и посмотреть на изменения в производительности работы сервера ESX с хранилищем StarWind Enterprise.
Скачать StarWind Enterprise HA можно по этой ссылке, ну а покупают его только здесь.
Вне зависимости от издания VMware ESXi 4.1 (будь то бесплатная версия, или лицензия Enterprise Plus), доступна функция Configuration-Software=-Virtual Machine Startup/Shutdown (рис.1), которая позволяет отработать ситуацию с выключением питания на физическом сервере и автоматически запускает виртуальные машины... Таги: VMware, VMachines, vSphere, Script, Blogs, HA
Мы уже много писали о продукте StarWind Enterprise HA, который позволяет создавать отказоустойчивые хранилища для серверов виртуализации VMware ESX на базе обычных Windows-серверов. Недавно вышла версия StarWind Enterprise HA 5.5, в которой реализован канал Heartbeat для еще большей надежности продукта. В данной статье рассматривается весь процесс создания отказоустойчивого кластера StarWind, который выдерживает отказ одного из узлов, отвечающего за работу с томами VMFS для серверов ESX / ESXi.
Таги: StarWind, Enterprise, HA, Storage, iSCSI, VMware, ESX, vSphere
Как многие из вас знают, есть такой замечательный продукт StarWind Enterprise, который позволяет создать отказоустойчивый кластер хранилищ для виртуальных машин VMware vSphere. Об этом продукте у нас есть целый раздел, но наиболее полезные страницы - это эта, эта, эта и эта.
Схема организации кластера высокой доступности хранилищ StarWind Enterprise выглядит так:
То есть, каждый из узлов StarWind должен иметь, по крайней мере, 2 сетевых интерфейса - для доступа хост-серверов виртуализации к хранилищу и для синхронизации данных узлов между собой (чтобы работа продолжилась в случае отказа одного из узлов - данные пишутся на узлы синхронно). Но само собой, 2 интерфейса - это очень ненадежно и небыстро. Поэтому лучше делать NIC Teaming и для канала синхронизации (надежность), и для канала работы с хранилищем по iSCSI (скорость). Поэтому, по-хорошему, нужно 4 интерфейса.
Вы уже все, конечно же, скачали версию StarWind Enterprise 5.5 и приступили к ее установке. Где определяются параметры сетевых интерфейсов? Запустим, например, мастер создания виртуального диска, работающего в режиме высокой доступности (High Availability):
Здесь указываются параметры сервера-партнера в кластере высокой доступности. Имя или IP-адрес, который сюда вводится - это и есть интерфейс узла, через который происходит доступ со стороны хост-серверов VMware ESX (то есть то, что на предыдущей картинке сверху). А вот в этом шаге мастера:
В поле "Интерфейс" указывается IP-адрес интерфейса, по которому происходит синхронизация узлов между собой (то, что на первой картинке сбоку). Кроме того, в версии 5.5 появилось новое поле Heartbeat - это интерфейс, через который два узла кластера Heartbeat обмениваются сигналами доступности, чтобы при обрыве канала синхронизации не возникло ситуации Split Brain (понять что это такое вы можете из статьи "Новая возможность StarWind Enterprise HA - устранение ситуации Split Brain"). Вот в поле Heartbeat этот адрес и нужно задавать. Само собой, лучше, если подсеть heartbeat у вас будет отдельная в целях повышения надежности.
Кстати, заметьте, что есть галка "Auto synchronization after failure", которая позволяет в случае отказа одного из узлов, а потом ввод его в строй (например, перезагрузка) автоматически синхронизировать узлы между собой. Раньше это делалось только вручную.
И еще одно - вы уже заметили, что на картинках меню на русском языке. Переключается язык тут:
Мелочь, а приятно.
Таги: StarWind, Enterprise, HA, VMware, ESX, iSCSI, Storage
Сегодня должен быть доступен релиз продукта StarWind Enterprise HA версии 5.5, который позволяет превратить любой Windows-сервер в отказоустойчивое хранилище данных для хост-серверов VMware ESX или Microsoft Hyper-V, работающее по протоколу iSCSI (а значит, не надо вкладывать деньги в дорогостоящие Fibre Channel хранилища). Подробнее о продукте можно прочитать тут, тут, тут, тут и тут (и, вообще, есть для этого специальный раздел на сайте).
Новые возможности StarWind Enterprise HA 5.5:
High Availability: Добавлена возможность устранения ситуации Split Brain (в случае обрыва канала синхронизации). Теперь в случае отсутствия связи между узлами по сети синхронизации StarWind обрабатывает эту ситуацию с помощью сигналов доступности (Heartbeat) по сети взаимодействия с хост-серверами.
Если в этой сети обнаруживается, что второй узел доступен, а недоступен только канал синхронизации, то первичный узел кластера StarWind продолжает запись данных виртуальных машин, а вторичный узел отключает всех своих клиентов. Таким образом сохраняется целостность кластера и отсутствует потери данных, а также простои виртуальных машин. Тем не менее, для канала синхронизации все равно лучше использовать несколько сетевых интерфейсов и NIC Teaming.
High Availability: множественные улучшения производительности работы кластера StarWind.
High Availability: поддержка собственной технологии Fast Sync для устройств работающих в режиме кэширования write-back (подробнее здесь). Эта технология позволяет в случае наступления события отказа одного из узлов кластера хранилищ StarWind, а затем его восстановлении (Failback) сделать быструю синхронизацию резервного узла с основным за счет передачи только изменений с момента последнего "живого" состояния основного узла. А вообще методов кэширования в StarWind iSCSI есть два (и они, в зависимости от нагрузки, увеличивают производительность до 30-50%):
High Availability: Если оба узла кластера хранилища StarWind iSCSI отказали или выпали из сети, и после этого начала работать полная синхронизация этих узлов, то устройства хранения будут доступны хост-серверам ESX или Hyper-V сразу же (до ее окончания). Данные будут записываться на узел, который выбран в качестве источника синхронизации (synchronization source).
High Availability: Добавлена полная поддержка аутентификации в iSCSI SAN по паролю (CHAP authentication).
CDP/Snapshots: Доработан механизм работы с дисками с GPT разделами.
Virtual Tape: Исправлена ошибка, связанная с изменением образа файла virtual tape. Параметры устройства теперь показывают корректное имя файла. Если в устройство не загружено ни одного файла-образа Virtual Tape, то в свойствах отображается "None - Virtual Tape device is not loaded" и нулевой размер файла.
GUI: Множество добавлений и исправлений в основное средство управления - Management Console.
Скачать пробную версию StarWind Enterprise HA 5.5 можно по этой ссылке. Ну а продается StarWind в компании VMC.
Таги: StarWind, Enterprise, Update, HA, iSCSI, Storage, ESX, Hyper-V, VMware, Microsoft
Многим из вас уже известно средство создания отказоустойчивых хранилищ для серверов VMware vSphere - StarWind Enterprise HA. Оно позволяет при минимальных вложениях создать инфраструктуру хранения данных для виртуальных машин на базе обычного Windows-сервера посредством технологии iSCSI и защитить ее от сбоев со стороны систем хранения (локальные диски серверов или общие хранилища).
Сегодня я хочу поговорить об экономической стороне дела. Не все организации из сектора среднего и малого бизнеса могут позволить себе дорогостоящие хранилища HP или EMC (и их дублирование!), при этом для некоторых сервисов очень важна высокая доступность на всех уровнях от сервера до хранилища. То есть они не могут простаивать ни минуты.
В VMware vSphere есть механизм защиты от сбоев серверов - VMware HA, который перезапустит виртуальную машину отказавшего или выпавшего из сети сервера на других серверах кластера. А вот как быть с хранилищами? Можно использовать StarWind iSCSI Target для создания VMFS-тома на локальном хранилище одного из физических серверов (или прицепленного к нему тома общего хранилища) - но это не убережет от сбоев. Можно использовать кластер StarWind Enterprise HA из двух серверов - тогда конфигурация будет отказоустойчивой со стороны хранилищ, но потребуются деньги на эти 2 сервера.
Некоторые организации нашли выход - они размещают виртуальные машины с установленным в них StarWind Enterprise HA на разных хостах ESX в кластере VMware HA и делают между этими ВМ кластер StarWind. Сами виртуальные машины со StarWind (с большими виртуальными дисками) лежат на разных физических хранилищах (например, это могут быть локальные диски каждого из хостов ESX).
Такая конфигурация, безусловно, дает некоторое падение производительности при работе с дисками - поскольку есть несколько уровней виртуализации хранилищ, но зато позволяет вообще без вложений обеспечить отказоустойчивость на уровне системы хранения. Тем более, что, например, локальные диски хостов ESX в этом случае работают достаточно быстро.
Если один хост ESX откажет - не беда его виртуальные машины автоматически перезапустятся с помощью VMware HA на другом хосте, а данные ВМ будут доступны со второго узла. Понятно, что на таких хранилищах можно держать не все виртуальные машины, а только те, за которые особенно страшно. Есть такие клиенты у StarWind, которые таким образом обеспечивают Server HA и Storage HA - и всем довольны.
И кстати - через какое-то время у StarWind будет VSA (Virtual Storage Appliance), который будет представлять собой такую вот виртуальную машину, используемую как хранилище, но на базе какого-нибудь Linux, а значит не придется тратить деньги на лицензию Microsoft Windows.
Пробную версию StarWind Enterprise HA можно скачать по этой ссылке.
Таги: StarWind, HA, Storage, vSphere, ESX, iSCSI, SMB, VMachines
В прошлой заметке мы писали о том, какие типы дисков бывают в продукте StarWind Enterprise, позволющем создать отказоустойчивую инфраструктуру хранения данных виртуальных машин серверов VMware ESX или Microsoft Hyper-V.
Сегодня мы посмотрим на мастер создания виртуального диска с поддержкой мгновенных снимков (снапшотов), который будет предоставлять доступ хост-серверам виртуализации по iSCSI. Снапшоты могут оказаться полезными при разработке и тестировании (временные снапшоты хранилищ виртуальных машин), а также для защиты данных от утери или сбоев в виртуальной инфраструктуре.
Для данного типа диска важен параметр Operation Mode, который задает режим его работы. Этот диск в StarWind Enterprise может работать в одном из четырех режимов:
Growing Image (Thin Provisioning) - образ диска на физическом устройстве будет создан минимального объема (тонкий диск). Для серверов ESX он будет виден как полноценное хранилище указанного объема, а сам файл образа будет расти по мере его наполнения данными. Снапшот хранилища можно сделать только вручную. Для этого из контекстного меню для устройства на iSCSI Target надо выбрать пункт Create Snapshot. Этот режим работы диска подходит для создания снимков хранилища при тестировании каких-нибудь обновлений или глобальных изменений в прикладных системах виртуальных машин.
Auto-Restored Snapshot - данный тип диска как раз подходит для разработки и тестирования. В таком режиме хранилище виртуальных машин во время одной сессии iSCSI будет изначально работать в режиме снапшота, а при окончании сессии - снапшот откатится к изначальному состоянию. Представьте, например, что вы тестируете связку систем на хранилище, но не хотите вносить изменения в эталонный виртуальный диск. Для такого диска можно задать лимит хранимых снапшотов (опция Limit maximum number of stored snapshots).
Snapshot and CDP - в таком режиме StarWind будет автоматически создавать снапшоты хранилищ с заданным интервалом времени (опция Snapshot auto creation with interval of (minutes)). Такой тип диска полезен для постоянной защиты данных (Continuous Data Protection, CDP) хранилищ виртуальных машин от их утери или порчи. В случае сбоя можно откатиться к нужному снапшоту.
Read-Only - такой диск будет доступен только для чтения, и для него нельзя будет создать снапшот. Этот диск подходит для создания хранилищ с какими-нибудь дистрибутивами или шаблонами, куда не потребуется вносить изменения.
Теперь что касается восстановления хранилищ из снапшотов. Пока восстанавливать их из интерфейса StarWind нельзя (как, например, дерево снапшотов в VMware vSphere). Чтобы восстановить хранилище, вам понадобится пересоздать iSCSI Target и указать существующих виртуальный диск снапшота в папке с данным диском. В скором времени нам обещают восстановление снапшотов из GUI продукта StarWind.
Скачать пробную версию ПО StarWind Enteprise HA можно по этой ссылке. Купить StarWind можно в компании VMC.

 RSS
RSS